

Modificáronse 100 ficheiros con 294 adicións e 30321 borrados
BIN=BIN
.claude/.DS_Store
+ 0
- 111
.claude/agents/agent-implements-agent.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 143
.claude/agents/function-implements-agent.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 182
.claude/agents/tool-implements-agent.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 54
.claude/commands/coding-technical-implement-based-langgraph.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 81
.claude/commands/component-arc.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 41
.claude/commands/dynamic-project-init.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 51
.claude/commands/prd-technical-implement-based-langgraph.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 47
.claude/commands/tools-generate.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 37
.claude/settings.local.json
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 114
- 0
README.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
BIN=BIN
arc.png
{kind=link}
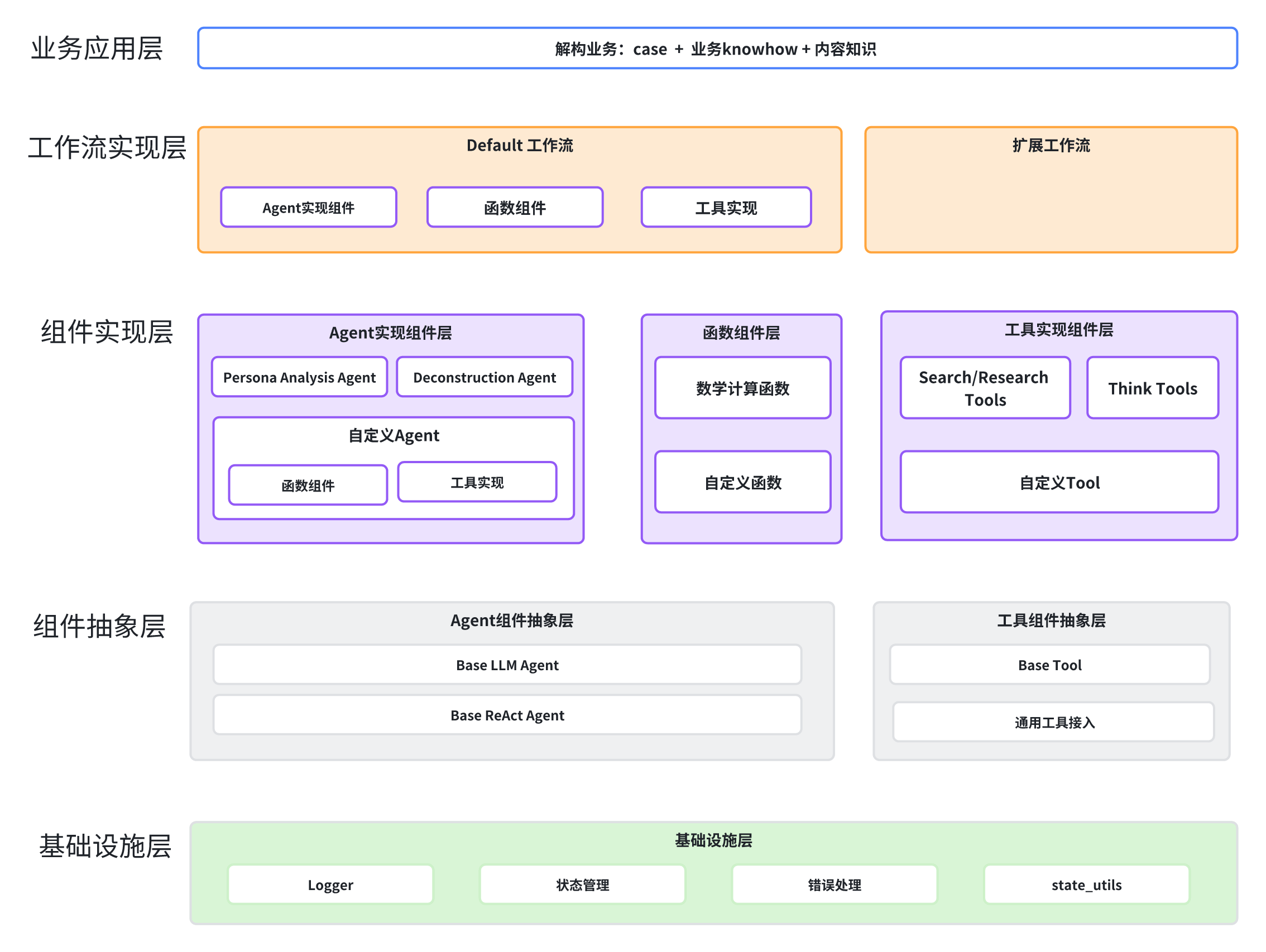
+ 0
- 106
decode_task/decodeTask.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 100
decode_task/evaluateTask.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 120
decode_task/topicTask.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 1003
decode_workflow_process.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 58
doc/command
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 295
doc/record
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 33
doc/脚本.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 35
doc/脚本点
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
BIN=BIN
examples/.DS_Store
+ 0
- 7
examples/demo.json
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 108
examples/demo_default.json
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
BIN=BIN
examples/html/.DS_Store
+ 0
- 1931
examples/html/visualize/script.js
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 2871
examples/html/visualize/style.css
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 133
examples/run_batch_script_v2.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 264
examples/run_decode_script.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 298
examples/run_evaluate.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 0
examples/static/visualize/__init__.py
+ 0
- 556
examples/static/visualize/tab1.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 176
examples/static/visualize/tab2.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 1926
examples/static/visualize/tab3.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 956
examples/static/visualize/tab5.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 2
examples/static/visualize_v2/__init__.py
|
||
|
||
|
||
+ 0
- 176
examples/static/visualize_v2/tab1.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 155
examples/static/visualize_v2/tab2.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 196
examples/static/visualize_v2/tab3.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 67
examples/static/visualize_v2/tab4.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 162
examples/use_decode_video_model.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 429
examples/visualize_script_results.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 285
examples/visualize_script_results_v2.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 210
loggers/sls.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 65
- 259
main.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 30
models/decode_record.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 67
- 0
models/decode_task_result.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 40
models/decode_workflow.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 32
models/evaluate_record.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 37
- 0
models/task.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
BIN=BIN
prd1.4.pdf
+ 11
- 21
requirements.txt
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
BIN=BIN
src/.DS_Store
+ 0
- 0
src/__init__.py
BIN=BIN
src/components/.DS_Store
+ 0
- 223
src/components/README.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 99
src/components/__init__.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 38
src/components/agents/__init__.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 396
src/components/agents/base.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 222
src/components/agents/content_unit_split_agent.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 255
src/components/agents/content_unit_understand.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 347
src/components/agents/evaluate_agent.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 903
src/components/agents/inspiration_points_agent.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 720
src/components/agents/key_points_agent.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 238
src/components/agents/purpose_point_agent.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 1101
src/components/agents/recursive_image_deconstruction_agent.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 691
src/components/agents/recursive_text_deconstruction_agent.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 1735
src/components/agents/script_form_extraction_agent.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 164
src/components/agents/script_keyword_agent.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 254
src/components/agents/script_section_division_agent.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 1726
src/components/agents/script_substance_extraction_agent.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 380
src/components/agents/search_keyword_agent.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 196
src/components/agents/structure_agent.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 581
src/components/agents/topic_selection_understanding_agent.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 49
src/components/functions/__init__.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 394
src/components/functions/base.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 238
src/components/functions/json_utils.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 323
src/components/functions/result_aggregation_function.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 299
src/components/functions/video_upload_function.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 72
src/components/tools/__init__.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 381
src/components/tools/base.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 235
src/components/tools/knowledge_retrieval_tools.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 160
src/components/tools/nanobanana_tools.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 156
src/components/tools/segment_tools.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 315
src/models/README.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 21
src/models/__init__.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 129
src/models/database.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 195
src/models/decode_video.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 156
src/models/evaluate_record.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 11
src/states/__init__.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 57
src/states/script_state.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 209
src/states/what_deconstruction_state.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 17
src/utils/__init__.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 110
src/utils/json_extractor.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 346
src/utils/llm_invoker.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 149
src/utils/logger.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 21
src/utils/utils.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 10
src/workflows/__init__.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 1499
src/workflows/decode_workflow.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 430
src/workflows/evaluate_workflow.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 0
- 283
src/workflows/script_workflow_v2.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||