
index.md 11 KB


!!! info "Aviso de Licencia" Este código y sus pesos de modelo asociados se publican bajo FISH AUDIO RESEARCH LICENSE. Por favor, consulta LICENSE para más detalles. Tomaremos acciones contra cualquier violación de la licencia.
!!! warning "Aviso Legal" No asumimos ninguna responsabilidad por el uso ilegal de este código. Por favor, consulta las leyes locales sobre DMCA y otras leyes relacionadas.
Inicio Rápido
Para Humanos
Aquí están los documentos oficiales de Fish Audio S2, sigue las instrucciones para comenzar fácilmente.
- Instalación
- Inferencia por Línea de Comandos
- Inferencia con WebUI
- Inferencia en Servidor
- Configuración con Docker
[!IMPORTANT] Para el servidor SGLang, por favor lee SGLang-Omni README.
Para Agente LLM
Instala y configura Fish-Audio S2 siguiendo las instrucciones aquí: https://speech.fish.audio/install/
Fish Audio S2
Mejor sistema de texto a voz entre código abierto y cerrado
Fish Audio S2 es el modelo más reciente desarrollado por Fish Audio. Entrenado con más de 10 millones de horas de audio en aproximadamente 50 idiomas, S2 combina alineación mediante aprendizaje por refuerzo con una arquitectura Dual-Autoregresiva para generar voz natural, realista y emocionalmente rica.
S2 soporta control detallado en línea de prosodia y emoción usando etiquetas en lenguaje natural como [laugh], [whispers] y [super happy], así como generación nativa multi-hablante y multi-turno.
Visita el sitio web de Fish Audio para el playground en vivo. Lee el blog para más detalles.
Variantes del Modelo
| Modelo | Tamaño | Disponibilidad | Descripción |
|---|---|---|---|
| S2-Pro | 4B parámetros | HuggingFace | Modelo insignia con todas las funcionalidades, máxima calidad y estabilidad |
Más detalles del modelo pueden encontrarse en el reporte técnico.
Resultados de Benchmark
| Benchmark | Fish Audio S2 |
|---|---|
| Seed-TTS Eval — WER (Chino) | 0.54% (mejor global) |
| Seed-TTS Eval — WER (Inglés) | 0.99% (mejor global) |
| Test de Turing de Audio (con instrucción) | 0.515 media posterior |
| EmergentTTS-Eval — Win Rate | 81.88% (más alto global) |
| Fish Instruction Benchmark — TAR | 93.3% |
| Fish Instruction Benchmark — Calidad | 4.51 / 5.0 |
| Multilenguaje (MiniMax Testset) — Mejor WER | 11 de 24 idiomas |
| Multilenguaje (MiniMax Testset) — Mejor SIM | 17 de 24 idiomas |
En Seed-TTS Eval, S2 logra el menor WER entre todos los modelos evaluados incluyendo sistemas cerrados: Qwen3-TTS (0.77/1.24), MiniMax Speech-02 (0.99/1.90), Seed-TTS (1.12/2.25). En el Test de Turing de Audio, 0.515 supera a Seed-TTS (0.417) en un 24% y a MiniMax-Speech (0.387) en un 33%. En EmergentTTS-Eval, S2 obtiene resultados particularmente fuertes en paralingüística (91.61% win rate), preguntas (84.41%) y complejidad sintáctica (83.39%).
Características Destacadas
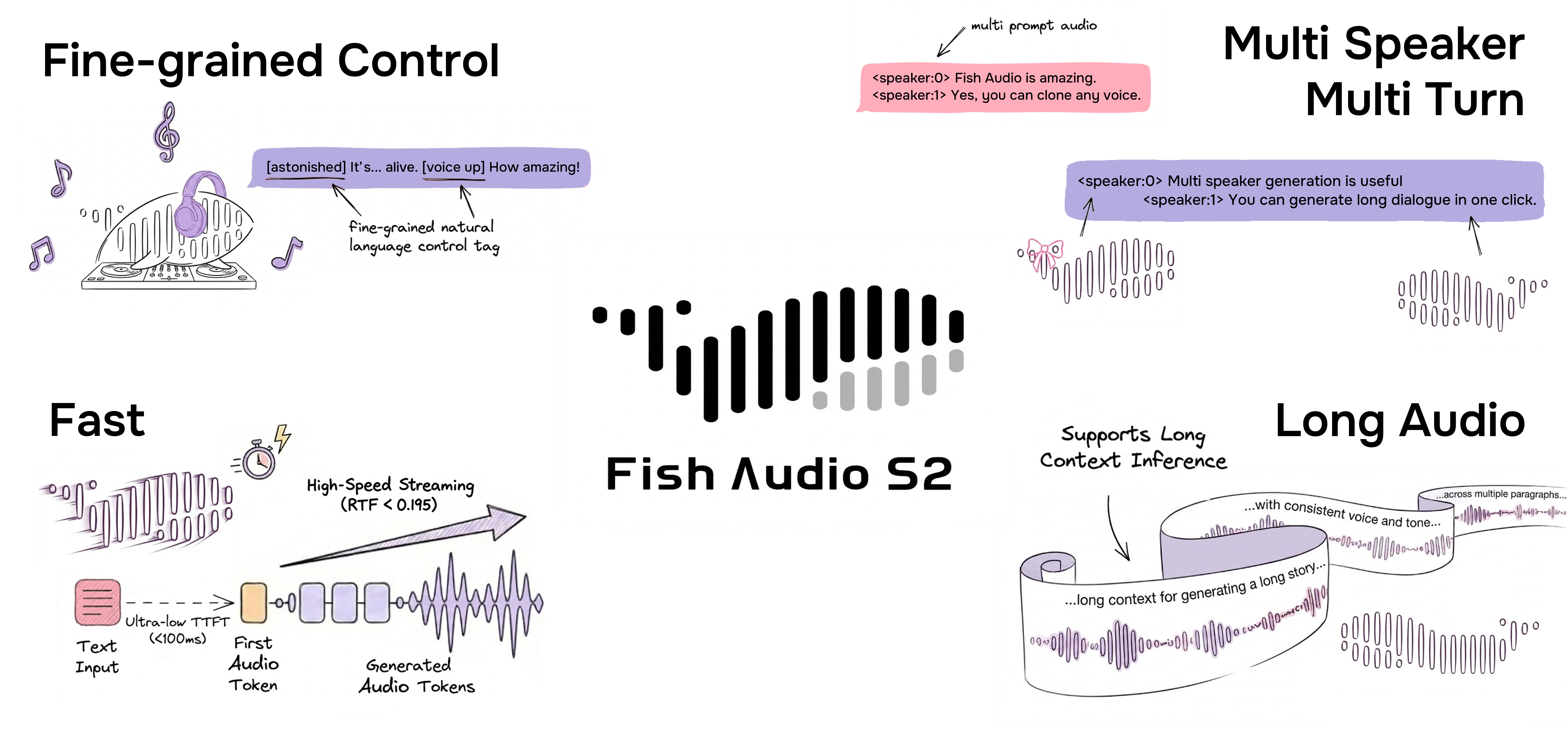
Control Fino en Línea mediante Lenguaje Natural
S2 permite control localizado sobre la generación de voz incrustando instrucciones en lenguaje natural directamente en posiciones específicas del texto. En lugar de depender de un conjunto fijo de etiquetas, S2 acepta descripciones libres como [whisper in small voice], [professional broadcast tone] o [pitch up], permitiendo control expresivo abierto a nivel de palabra.
Arquitectura Dual-Autoregresiva
S2 se basa en un transformer solo-decoder combinado con un códec de audio basado en RVQ (10 codebooks, ~21 Hz). La arquitectura Dual-AR divide la generación en dos etapas:
- AR Lento opera en el eje temporal y predice el codebook semántico principal.
- AR Rápido genera los 9 codebooks residuales restantes en cada paso temporal, reconstruyendo detalles acústicos finos.
Este diseño asimétrico — 4B parámetros en el eje temporal y 400M en el eje de profundidad — mantiene la inferencia eficiente sin perder fidelidad.
Alineación con Aprendizaje por Refuerzo
S2 utiliza Group Relative Policy Optimization (GRPO) para alineación post-entrenamiento. Los mismos modelos usados para filtrar y anotar datos se reutilizan como modelos de recompensa durante RL, eliminando desajustes de distribución. La señal de recompensa combina precisión semántica, cumplimiento de instrucciones, preferencia acústica y similitud de timbre.
Streaming en Producción con SGLang
Debido a que la arquitectura Dual-AR es estructuralmente isomórfica a los LLM autoregresivos estándar, S2 hereda optimizaciones como batching continuo, caché KV paginado, CUDA graph replay y caching de prefijos basado en RadixAttention.
En una sola GPU NVIDIA H200:
- RTF: 0.195
- Tiempo hasta primer audio: ~100 ms
- Throughput: 3,000+ tokens acústicos/s manteniendo RTF < 0.5
Soporte Multilenguaje
S2 soporta texto a voz multilenguaje de alta calidad sin requerir fonemas ni preprocesamiento específico del idioma. Incluye:
Inglés, Chino, Japonés, Coreano, Árabe, Alemán, Francés...
¡Y MÁS!
La lista continúa expandiéndose, revisa Fish Audio para las últimas novedades.
Generación Multi-Hablante Nativa
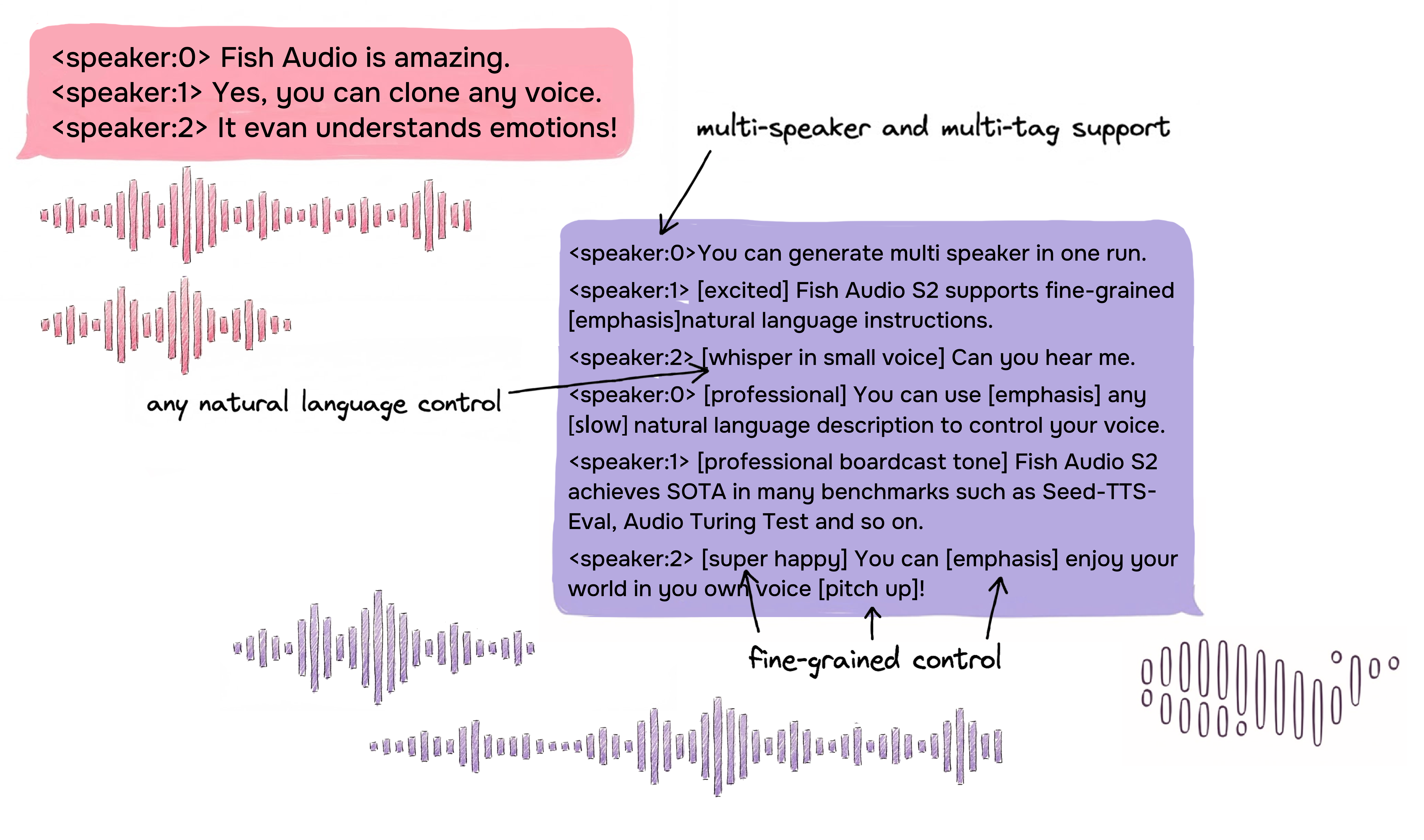
Fish Audio S2 permite a los usuarios subir audio de referencia con múltiples hablantes; el modelo gestionará las características de cada uno mediante el token <|speaker:i|>. Luego puedes controlar el comportamiento del modelo con ese identificador, permitiendo múltiples voces en una sola generación. Ya no necesitas subir audio por separado para cada hablante.
Generación Multi-Turno
Gracias a la expansión del contexto del modelo, ahora puede usar información previa para mejorar la expresividad del contenido generado, aumentando la naturalidad.
Clonación de Voz Rápida
Fish Audio S2 permite clonación de voz precisa usando una muestra corta (10–30 segundos). El modelo captura timbre, estilo y emoción, produciendo voces realistas y consistentes sin fine-tuning adicional.
Por favor consulta SGLang-Omni README para usar el servidor SGLang.
Créditos
Reporte Técnico
@misc{fish-speech-v1.4,
title={Fish-Speech: Leveraging Large Language Models for Advanced Multilingual Text-to-Speech Synthesis},
author={Shijia Liao and Yuxuan Wang and Tianyu Li and Yifan Cheng and Ruoyi Zhang and Rongzhi Zhou and Yijin Xing},
year={2024},
eprint={2411.01156},
archivePrefix={arXiv},
primaryClass={cs.SD},
url={https://arxiv.org/abs/2411.01156},
}
@misc{liao2026fishaudios2technical,
title={Fish Audio S2 Technical Report},
author={Shijia Liao and Yuxuan Wang and Songting Liu and Yifan Cheng and Ruoyi Zhang and Tianyu Li and Shidong Li and Yisheng Zheng and Xingwei Liu and Qingzheng Wang and Zhizhuo Zhou and Jiahua Liu and Xin Chen and Dawei Han},
year={2026},
eprint={2603.08823},
archivePrefix={arXiv},
primaryClass={cs.SD},
url={https://arxiv.org/abs/2603.08823},
}