

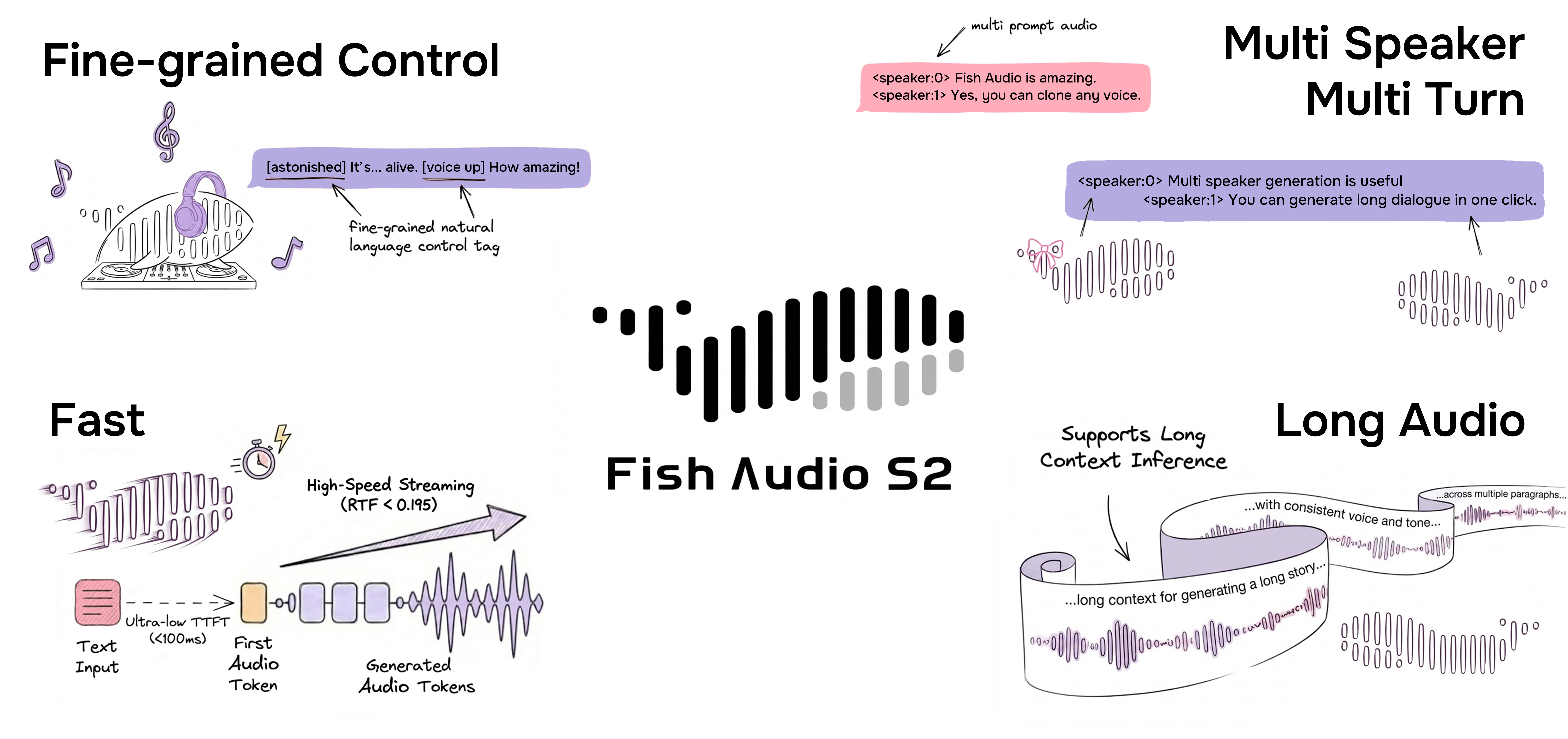
 ### 自然言語による細粒度インライン制御
Fish Audio S2 では、テキスト内の特定の単語やフレーズ位置に自然言語の指示を直接埋め込むことで、音声生成を局所的に制御できます。固定の事前定義タグに依存するのではなく、S2 は [whisper in small voice]、[professional broadcast tone]、[pitch up] のような自由形式のテキスト記述を受け付け、単語レベルで表現をオープンエンドに制御できます。
### 二重自己回帰(Dual-Autoregressive)アーキテクチャ
S2 はデコーダー専用 Transformer と RVQ ベースの音声コーデック(10 codebooks、約 21 Hz)を組み合わせています。Dual-AR は生成を 2 段階に分割します。
- **Slow AR** は時間軸方向に動作し、主となる semantic codebook を予測。
- **Fast AR** は各時刻で残り 9 個の residual codebook を生成し、細かな音響ディテールを復元。
この非対称設計(時間軸 4B パラメータ、深さ軸 400M パラメータ)により、音質を保ちながら推論効率を高めています。
### 強化学習アラインメント
S2 は後学習アラインメントに Group Relative Policy Optimization(GRPO)を採用しています。学習データのフィルタリングとアノテーションに使った同一モデル群を、そのまま RL の報酬モデルとして再利用することで、事前学習データ分布と事後学習目的のミスマッチを抑制しています。報酬信号には、意味的正確性、指示追従性、音響的選好スコア、音色類似度が含まれます。
### SGLang による本番向けストリーミング
Dual-AR は構造的に標準的な自己回帰 LLM と同型のため、S2 は SGLang の LLM 向け最適化をそのまま活用できます。たとえば continuous batching、paged KV cache、CUDA graph replay、RadixAttention ベースの prefix caching です。
単一の NVIDIA H200 GPU での実測:
- **RTF(Real-Time Factor):** 0.195
- **初回音声出力までの時間:** 約 100 ms
- **スループット:** RTF 0.5 未満を維持しつつ 3,000+ acoustic tokens/s
### 多言語サポート
Fish Audio S2 は、音素や言語固有の前処理を必要とせずに、高品質な多言語テキスト読み上げをサポートします。以下を含みます:
**英語、中国語、日本語、韓国語、アラビア語、ドイツ語、フランス語...**
**さらに多く!**
リストは常に拡大しています。最新のリリースについては [Fish Audio](https://fish.audio/) を確認してください。
### ネイティブなマルチスピーカー生成
### 自然言語による細粒度インライン制御
Fish Audio S2 では、テキスト内の特定の単語やフレーズ位置に自然言語の指示を直接埋め込むことで、音声生成を局所的に制御できます。固定の事前定義タグに依存するのではなく、S2 は [whisper in small voice]、[professional broadcast tone]、[pitch up] のような自由形式のテキスト記述を受け付け、単語レベルで表現をオープンエンドに制御できます。
### 二重自己回帰(Dual-Autoregressive)アーキテクチャ
S2 はデコーダー専用 Transformer と RVQ ベースの音声コーデック(10 codebooks、約 21 Hz)を組み合わせています。Dual-AR は生成を 2 段階に分割します。
- **Slow AR** は時間軸方向に動作し、主となる semantic codebook を予測。
- **Fast AR** は各時刻で残り 9 個の residual codebook を生成し、細かな音響ディテールを復元。
この非対称設計(時間軸 4B パラメータ、深さ軸 400M パラメータ)により、音質を保ちながら推論効率を高めています。
### 強化学習アラインメント
S2 は後学習アラインメントに Group Relative Policy Optimization(GRPO)を採用しています。学習データのフィルタリングとアノテーションに使った同一モデル群を、そのまま RL の報酬モデルとして再利用することで、事前学習データ分布と事後学習目的のミスマッチを抑制しています。報酬信号には、意味的正確性、指示追従性、音響的選好スコア、音色類似度が含まれます。
### SGLang による本番向けストリーミング
Dual-AR は構造的に標準的な自己回帰 LLM と同型のため、S2 は SGLang の LLM 向け最適化をそのまま活用できます。たとえば continuous batching、paged KV cache、CUDA graph replay、RadixAttention ベースの prefix caching です。
単一の NVIDIA H200 GPU での実測:
- **RTF(Real-Time Factor):** 0.195
- **初回音声出力までの時間:** 約 100 ms
- **スループット:** RTF 0.5 未満を維持しつつ 3,000+ acoustic tokens/s
### 多言語サポート
Fish Audio S2 は、音素や言語固有の前処理を必要とせずに、高品質な多言語テキスト読み上げをサポートします。以下を含みます:
**英語、中国語、日本語、韓国語、アラビア語、ドイツ語、フランス語...**
**さらに多く!**
リストは常に拡大しています。最新のリリースについては [Fish Audio](https://fish.audio/) を確認してください。
### ネイティブなマルチスピーカー生成
 Fish Audio S2 では、ユーザーが複数のスピーカーを含む参照オーディオをアップロードでき、モデルは `<|speaker:i|>` トークンを介して各スピーカーの特徴を処理します。その後、スピーカーIDトークンを使用してモデルのパフォーマンスを制御し、1回の生成で複数のスピーカーを含めることができます。以前のように各スピーカーに対して個別に参照オーディオをアップロードして音声を生成する必要はもうありません。
### マルチターン対話生成
モデルのコンテキストの拡張により、以前の情報を使用して後続の生成されたコンテンツの表現力を向上させ、コンテンツの自然さを高めることができるようになりました。
### 高速音声クローニング
Fish Audio S2 は、短い参照サンプル(通常10〜30秒)を使用した正確な音声クローニングをサポートしています。モデルは音色、話し方、感情的な傾向を捉え、追加の微調整なしでリアルで一貫したクローン音声を生成します。
SGLang サーバーの利用については [SGLang-Omni README](https://github.com/sgl-project/sglang-omni/blob/main/sglang_omni/models/fishaudio_s2_pro/README.md) を参照してください。
---
## クレジット
- [VITS2 (daniilrobnikov)](https://github.com/daniilrobnikov/vits2)
- [Bert-VITS2](https://github.com/fishaudio/Bert-VITS2)
- [GPT VITS](https://github.com/innnky/gpt-vits)
- [MQTTS](https://github.com/b04901014/MQTTS)
- [GPT Fast](https://github.com/pytorch-labs/gpt-fast)
- [GPT-SoVITS](https://github.com/RVC-Boss/GPT-SoVITS)
- [Qwen3](https://github.com/QwenLM/Qwen3)
## 技術レポート
```bibtex
@misc{fish-speech-v1.4,
title={Fish-Speech: Leveraging Large Language Models for Advanced Multilingual Text-to-Speech Synthesis},
author={Shijia Liao and Yuxuan Wang and Tianyu Li and Yifan Cheng and Ruoyi Zhang and Rongzhi Zhou and Yijin Xing},
year={2024},
eprint={2411.01156},
archivePrefix={arXiv},
primaryClass={cs.SD},
url={https://arxiv.org/abs/2411.01156},
}
@misc{liao2026fishaudios2technical,
title={Fish Audio S2 Technical Report},
author={Shijia Liao and Yuxuan Wang and Songting Liu and Yifan Cheng and Ruoyi Zhang and Tianyu Li and Shidong Li and Yisheng Zheng and Xingwei Liu and Qingzheng Wang and Zhizhuo Zhou and Jiahua Liu and Xin Chen and Dawei Han},
year={2026},
eprint={2603.08823},
archivePrefix={arXiv},
primaryClass={cs.SD},
url={https://arxiv.org/abs/2603.08823},
}
```
Fish Audio S2 では、ユーザーが複数のスピーカーを含む参照オーディオをアップロードでき、モデルは `<|speaker:i|>` トークンを介して各スピーカーの特徴を処理します。その後、スピーカーIDトークンを使用してモデルのパフォーマンスを制御し、1回の生成で複数のスピーカーを含めることができます。以前のように各スピーカーに対して個別に参照オーディオをアップロードして音声を生成する必要はもうありません。
### マルチターン対話生成
モデルのコンテキストの拡張により、以前の情報を使用して後続の生成されたコンテンツの表現力を向上させ、コンテンツの自然さを高めることができるようになりました。
### 高速音声クローニング
Fish Audio S2 は、短い参照サンプル(通常10〜30秒)を使用した正確な音声クローニングをサポートしています。モデルは音色、話し方、感情的な傾向を捉え、追加の微調整なしでリアルで一貫したクローン音声を生成します。
SGLang サーバーの利用については [SGLang-Omni README](https://github.com/sgl-project/sglang-omni/blob/main/sglang_omni/models/fishaudio_s2_pro/README.md) を参照してください。
---
## クレジット
- [VITS2 (daniilrobnikov)](https://github.com/daniilrobnikov/vits2)
- [Bert-VITS2](https://github.com/fishaudio/Bert-VITS2)
- [GPT VITS](https://github.com/innnky/gpt-vits)
- [MQTTS](https://github.com/b04901014/MQTTS)
- [GPT Fast](https://github.com/pytorch-labs/gpt-fast)
- [GPT-SoVITS](https://github.com/RVC-Boss/GPT-SoVITS)
- [Qwen3](https://github.com/QwenLM/Qwen3)
## 技術レポート
```bibtex
@misc{fish-speech-v1.4,
title={Fish-Speech: Leveraging Large Language Models for Advanced Multilingual Text-to-Speech Synthesis},
author={Shijia Liao and Yuxuan Wang and Tianyu Li and Yifan Cheng and Ruoyi Zhang and Rongzhi Zhou and Yijin Xing},
year={2024},
eprint={2411.01156},
archivePrefix={arXiv},
primaryClass={cs.SD},
url={https://arxiv.org/abs/2411.01156},
}
@misc{liao2026fishaudios2technical,
title={Fish Audio S2 Technical Report},
author={Shijia Liao and Yuxuan Wang and Songting Liu and Yifan Cheng and Ruoyi Zhang and Tianyu Li and Shidong Li and Yisheng Zheng and Xingwei Liu and Qingzheng Wang and Zhizhuo Zhou and Jiahua Liu and Xin Chen and Dawei Han},
year={2026},
eprint={2603.08823},
archivePrefix={arXiv},
primaryClass={cs.SD},
url={https://arxiv.org/abs/2603.08823},
}
```